سیستم جامع مانیتورینگ روتر
این سند داستان، قابلیتها، انواع متریکها و ساختار کار با متریک و لاگ در سیستم مانیتورینگ روتر را بهصورت یکپارچه توضیح میدهد تا مشتری بتواند ارزش و قابلیتهای راهحل را بهطور کامل درک کند.
داستان و ارزش راهحل
مشکل: روترها در شبکهٔ شما پراکندهاند؛ وضعیت سختافزار، دیتاپلن، سرویسها و لاگها معمولاً فقط روی خود دستگاه در دسترس است. برای دیدن سلامت کل شبکه باید به هر روتر جداگانه وصل شوید و دادهها را دستی جمع کنید.
راهحل: یک سیستم مانیتورینگ متمرکز که:
متریکها (وضعیت CPU، حافظه، دیسک، شبکه، دیتاپلن، فرایندها، IPsec) و لاگهای سیستم و سرویسها را از روترها جمعآوری میکند.
قبل از ارسال، دادهها را تگگذاری میکند (نام روتر، سایت، منبع) تا در سرور مانیتورینگ بتوانید بر اساس روتر یا سایت فیلتر و گروهبندی کنید.
همهٔ دادهها را به یک سرور مانیتورینگ (Prometheus + Loki + Grafana) میفرستد تا در یک داشبورد وضعیت چندین روتر و چند سایت را ببینید، کوئری بزنید و در صورت نیاز آلرت تعریف کنید.
ارزش برای مشتری: دید یکپارچه، صرفهجویی در زمان عملیاتی، عیبیابی سریعتر و امکان گزارشگیری و مانیتورینگ متمرکز بدون نیاز به لاگین به هر روتر.
قابلیتهای کلی
قابلیت |
توضیح |
|---|---|
جمعآوری یکپارچه |
متریکها و لاگها از یک pipeline واحد با تگ یکسان به سرور میروند. |
تگگذاری یکسان |
هر داده با |
متریکهای چندلایه |
لایهٔ host (CPU، حافظه، دیسک، شبکه)، لایهٔ دیتاپلن (VPP)، لایهٔ فرایند (سرویسها)، و لایهٔ امنیتی (IPsec/IKE). |
لاگ متمرکز |
لاگهای سیستم و سرویسها (از جمله journal، zebra، systemd) با برچسب منبع ( |
کوئری و نمودار |
با PromQL (متریک) و LogQL (لاگ) در Grafana میتوانید داشبورد، پنل لاگ و پنل نمودار بسازید. |
معماری و جریان داده

روتر: دادهها روی روتر تولید و قبل از ارسال پردازش و تگگذاری میشوند.
Mode = vector: همه sourceها (exporterها + لاگ) توسط Vector Client جمع میشوند؛ در سرور مانیتورینگ، متریکها به Prometheus و لاگها به Loki میروند.
Mode = tcp/udp: فقط لاگها به سرور Syslog ارسال میشوند و متریکها در این مسیر منتقل نمیشوند.
نمایش: Grafana از Prometheus و Loki داده میگیرد و برای داشبورد، نمودار و تحلیل استفاده میشود.
انواع متریکها
سیستم مانیتورینگ چند لایه متریک ارائه میدهد تا هم وضعیت host و هم دیتاپلن و سرویسها قابل رصد باشند.
لایه / منبع |
محتوا |
نمونه متریکها |
سند تفصیلی |
|---|---|---|---|
Node (سیستم و سختافزار) |
CPU، حافظه، دیسک، فایلسیستم، شبکه، systemd، زمان |
|
node_exporter_metrics_guide.md |
VPP (دیتاپلن) |
بافر، نودها، خطاها، جلسات، اینترفیس، ACL، WireGuard |
|
vpp_metrics_guide.md |
Process (فرایندها) |
CPU، حافظه، وضعیت بهتفکیک گروه فرایند (vpp، zebra، soolog و غیره) |
|
process_metrics_guide.md |
IPsec |
IKE SA، نیمهباز، صفها، وُرکرها، سلامت exporter |
|
ipsec_metrics_guide.md |
همهٔ این متریکها با برچسبهای یکسان (مثل monitor_name, monitor_site در صورت پیکربندی) در Prometheus در دسترس هستند و در Grafana میتوان با متغیرهای $site و $node یک داشبورد برای چند روتر و چند سایت ساخت.
ساختار کار با متریکها
برچسبها و انتخاب
متریکها با نام (مثلاً
node_cpu_seconds_total) و برچسب (مثلjob,instance,mode) در Prometheus ذخیره میشوند.در این پشته، برچسبهایی مثل monitor_name (روتر) و monitor_site (سایت) به متریکها اضافه میشوند تا فیلتر و گروهبندی در داشبورد ممکن شود.
زبان کوئری: PromQL
PromQL زبان کوئری Prometheus است: متریک را با نام و برچسب انتخاب میکنید، با توابعی مثل
rate(),sum(),avg()نرخ یا تجمیع محاسبه میکنید.نمونه برای نمودار استفادهٔ CPU:
rate(node_cpu_seconds_total{monitor_name="$node",monitor_site="$site"}[5m])
و باsum by (mode)یاavgمیتوان بهتفکیک حالت یا بهصورت تجمیعشده نمایش داد.
داشبورد و پنل نمودار
در Grafana یک دیتاسورس Prometheus تعریف میکنید و در پنلهای Time series (یا Graph) کوئری PromQL را وارد میکنید.
با تعریف متغیرهای
$siteو$nodeاز روی برچسبهای Prometheus، یک داشبورد برای همهٔ روترها و سایتها قابل استفاده است.
ساختار کار با لاگها
برچسبها و انتخاب
لاگها در Loki با برچسب ذخیره میشوند؛ در این پشته معمولاً:
monitor_site — سایت
monitor_name — روتر
monitor_identifier — منبع لاگ (مثل
systemd,zebra)
زبان کوئری: LogQL
LogQL شبیه PromQL است: ابتدا جریان لاگ را با
{monitor_site="$site",monitor_name="$node",monitor_identifier="systemd"}انتخاب میکنید.برای فیلتر متن:
|~ "error|failed"برای شمارش در زمان (نمودار):
count_over_time({...}[1m])برای پارس و قالببندی خط (مثلاً رویداد Track up/down):
| regexp "Track (?P<track>.*) .* (?P<state>up|down)$" | line_format "Track {{.track}} ==> {{.state}}"
پنل لاگ و پنل نمودار از لاگ
پنل Logs: کوئری LogQL با انتخابگر برچسب (و در صورت نیاز فیلتر یا قالببندی)؛ خروجی بهصورت لیست خطوط لاگ است.
پنل Time series از لاگ: با
count_over_time(... [1m])و کوئری نوع Range در Loki میتوان تعداد رویدادها را در زمان بهصورت نمودار نمایش داد.
جزئیات و نمونههای کامل در log_labels_values_guide.md و promql_logql_brief.md آمده است.
تنظیم سرور مانیتورینگ در روتر سودار
با دستور زیر میتوانید لاگهای روتر را به سرور مانیتورینگ ارسال کنید؛ در مدل یکپارچه علاوه بر لاگها، کلیه متریکهای سیستمی (CPU، RAM، دیسک، ترافیک شبکه و …) و متریکهای دیتاپلن سودار نیز در دسترس سرور مانیتورینگ قرار میگیرد. میتوانید آنها را در سرور مانیتورینگ دریافت کرده و در محیطی مانند Grafana (با دیتاسورس Prometheus) بهصورت نمودار در داشبورد نمایش دهید و تحلیل مناسبی از وضعیت روتر داشته باشید.
مدل یکپارچه (متریک + لاگ با Vector):
soodar1(config)# log syslog <server address> vector port 9000
توجه: متریکها توسط Prometheus از روتر scrape میشوند و همراه با لاگها توسط Vector به سرور مانیتورینگ ارسال میگردند.
مدل فقط لاگ (TCP/UDP به Syslog): اگر بخواهید از rsyslog (یا سرور Syslog دیگر) فقط برای دریافت لاگها استفاده کنید، دستور به شکل زیر است؛ در این حالت متریکها به سرور مانیتورینگ ارسال نمیشوند.
soodar1(config)# log syslog <server address> tcp|udp port PORT
(مقدار PORT و انتخاب tcp یا udp را متناسب با پیکربندی سرور Syslog خود قرار دهید.)
نمایش در Grafana (پنلها و تصاویر نمونه)
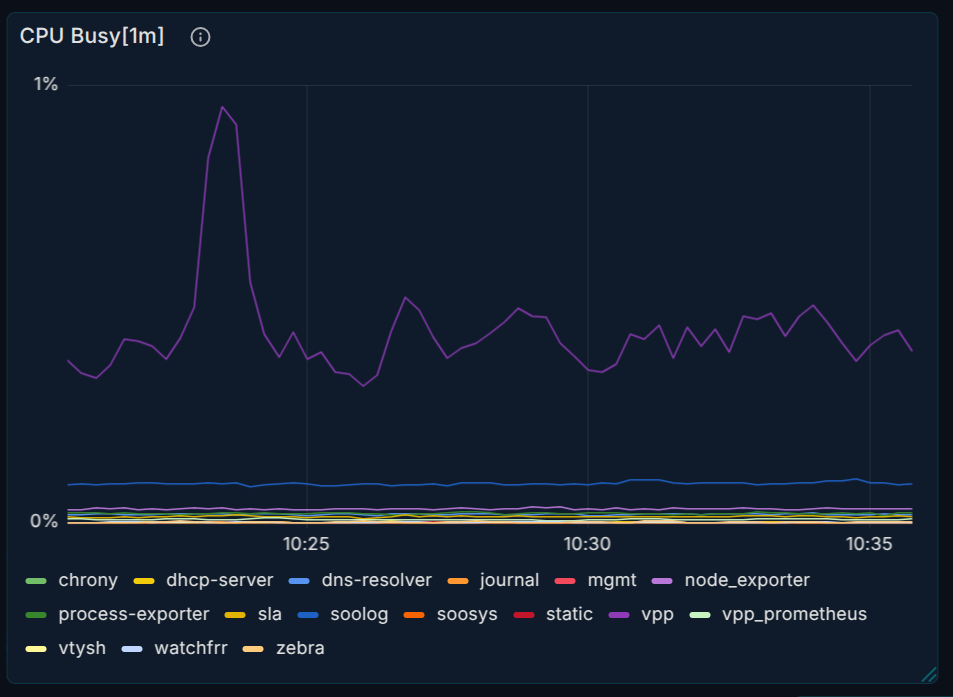
تصویر ۱: پنل متریک — نمودار CPU یا حافظه (Prometheus + PromQL)
چه چیزی نشان دهید: یک پنل Time series در Grafana که با PromQL متریکهای Node (مثلاً استفادهٔ CPU یا حافظهٔ آزاد) را برای یک یا چند روتر نمایش میدهد.
پیشنهاد محتوا:
کوئری نمونه:
(sum by (groupname) (rate(namedprocess_namegroup_cpu_seconds_total{monitor_site="$site",monitor_name="$node"}[1m]))/ scalar(count(count(node_cpu_seconds_total{monitor_site="$site",monitor_name="$node"}) by (cpu)))) *100میزان استفادهٔ CPU به ازای هر پروسهٔ در حال اجرا
تصویر ۲: پنل لاگ — لیست لاگها
کوئری نمایش تمامی لاگهای یک روتر:
{monitor_site="$site",monitor_name="$node"}
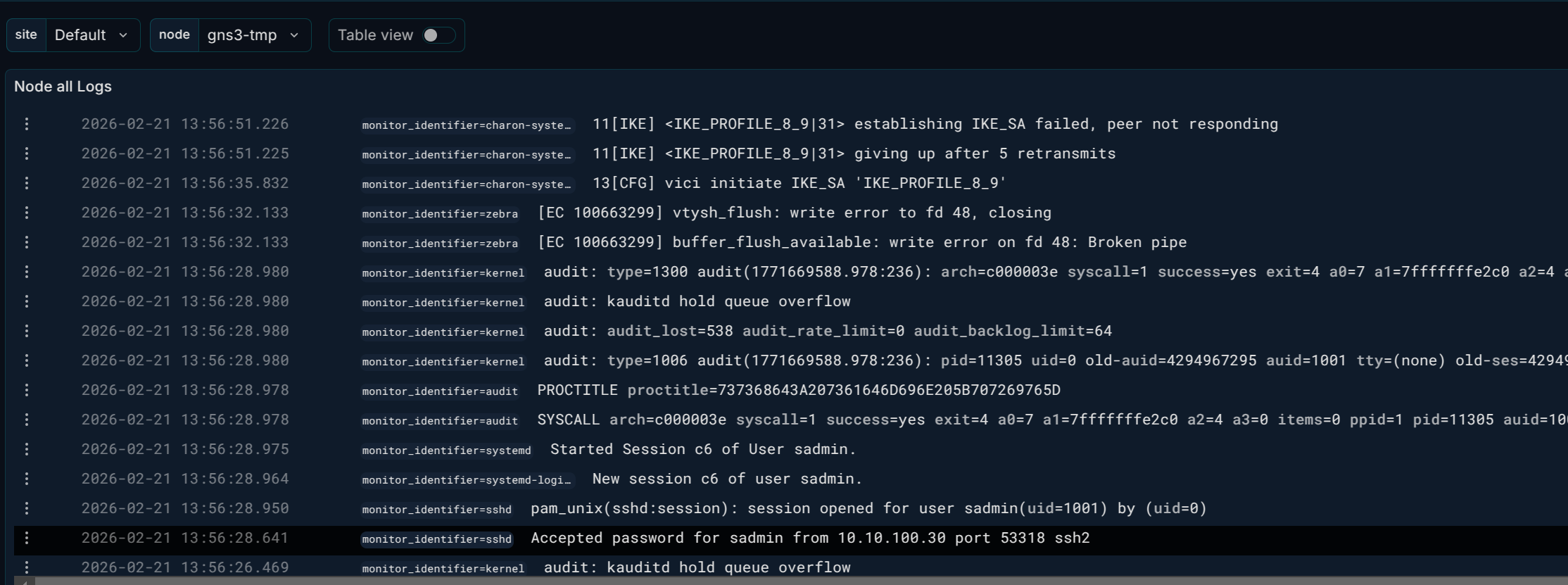
کوئری نمایش لاگهای SSH یک روتر:
{monitor_site="$site",monitor_name="$node",monitor_identifier="sshd"}

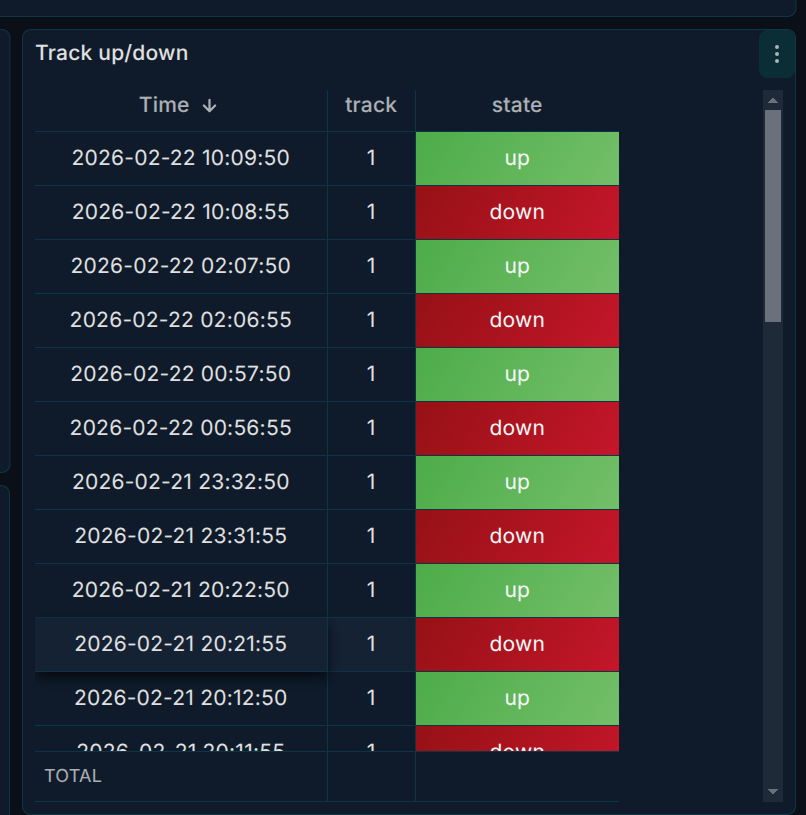
تصویر ۳: پنل جدول از لاگ — رویداد Track up/down
چه چیزی نشان دهید: یک پنل Time series (یا Graph) که با LogQL و مثلاً count_over_time(... [1m]) تعداد رویدادهای لاگ را در زمان نمایش میدهد؛ یا یک پنل Logs با خروجی پارسشده (مثلاً «Track N ==> up/down»).
پیشنهاد محتوا:
کوئری برای پردازش لاگ و استخراج مقادیر مورد نظر جهت نمایش در یک جدول:
{monitor_identifier="zebra",monitor_site="$site",monitor_name="$node"} |~ "(?i)Track\\s\\d{1,5}\\s(came up|went down)" | regexp "Track (?P<track>.*) .* (?P<state>up|down)$" | line_format "Track {{.track}} ==> {{.state}}"
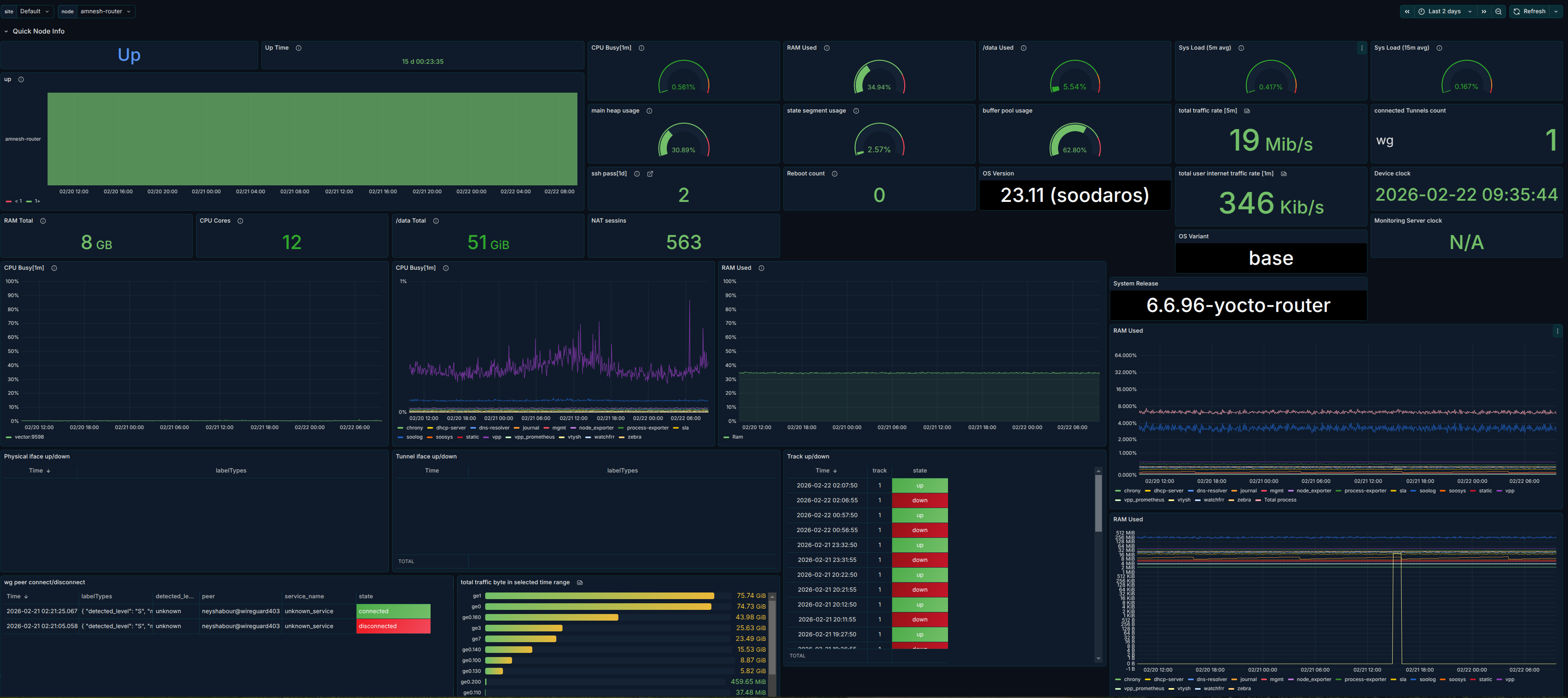
تصویر ۴: نمای کلی داشبورد
یک اسکرینشات از کل داشبورد Grafana که در آن چند پنل (مثلاً CPU، حافظه، لاگ و یک نمودار از لاگ) در یک صفحه دیده میشوند و متغیرهای $site و $node در بالای داشبورد انتخاب شدهاند.