Data Plane
برای چندین دهه، تنها راه برای سرعت بخشیدن به پردازش بسته ها افزودن سخت افزار سریعتر و یا استفاده از مدارهای مجتمع خاص منظوره( ASIC) بود. اما سرعت رشد سخت افزار با نیاز به سریعتر شدن پردازش بستهها متناسب نیست و استفاده از ASICها نیز باعث افزایش هزینهها و کاهش انعطاف پذیری دستگاهها میشود. اما پروژهای برای استفاده مفیدتر از سختافزارهای عمومی موجود برای پردازش بستهها وجود دارد: VPP.
با استفاده از پروژه متن باز VPP، دستگاه از طریق نرم افزاری که روی پردازنده های عمومی اجرا می شود، تا 100 برابر توان پردازش بسته بیشتر را ارائه می دهد. اما واقعا VPP چیست؟
پردازش بستهها در کرنل سیستم عامل:
تا مدتها مدل غالب پردازش بستهها پردازش مبتنی بر کرنل بوده است. برای هر دستگاه شبکهای که یک بسته را دریافت، بررسی و سپس به hop بعدی ارسال میکند، آن بسته در یک Interface شبکه دریافت می شود و مستقیما به سیستم عامل دستگاه ارسال میشود. این بسته تا کرنل سیستم عامل بالا میرود و در آنجا پردازش بسته انجام میگیرد.
هسته یا کرنل سیستم عامل، قلب تپندهی سیستم عامل است. این قسمت عملکرد کامپیوتر و سختافزارهای مهم آن( CPU و حافظه) را کنترل میکند. همچنین هستهی سیستم عامل نسبتا کوچک و بخش حساس و حیاتیای است و معمولا در هنگامی که پروسههای فراوانی نیاز به توجه دارند، بسیار مشغول است.
پردازش بسته ها در هسته بر مبنای اصل دریافت یک بسته در یک زمان، fetch کردن یک دستورالعمل از کش دستورالعملها، اجرای آن دستورالعمل روی بسته، fetch کردن دستورالعمل بعدی، اجرای آن دستورالعمل، و … طراحی شده است. سپس آن بسته به مقصد خود ارسال میشود و بسته دوم وارد می شود و همان روال را طی می کند.
تشبیه FD.io برای توضیح این موضوع خوب است: مساله پشته ای از الوار را در نظر بگیرید که در آن هر تکه الوار باید بریده شود، سنباده زده شود و سوراخ هایی در آن ایجاد شود. دو راه برای انجام کار وجود دارد: ۱- هر تخته را یکی یکی برش بزنید، سنباده بزنید و سوراخ کنید. یا، ۲- همه تخته ها را برش دهید، سپس همه تخته ها را سمباده بزنید، سپس همه تخته ها را سوراخ کنید. رویکرد دوم باعث صرفه جویی در زمان می شود زیرا از تغییر ابزارها با هر مرحله فرآیند در هر الوار جلوگیری می کنید.
پردازش مبتنی بر هسته رویکرد اول است. در پردازندههای قوی، بهعنوان مثال، پردازندههای کلاس Intel® Xeon®، ارسال بستهها با لینوکس به ۲ میلیون بسته در ثانیه (Mpps) میرسد - و به راحتی میتوان با قفل کردن هستههای CPU به یک پروسه یا درگیر کردن کرنل سیستم عامل این عدد را به شدت کاهش داد. با استفاده از برخی امکانات آزمایشی، لینوکس در برخی معیارها( مانند حذف همه بستههای دریافتی) دستاوردهایی دارد، اما هنوز کار زیادی برای رسیدن به بهرهوری بالا لازم است.
حال، اگر یکی از دستگاه های فوق دارای اینترفیس 10 گیگابیت بر ثانیه باشد، چگونه بسته ها را با سرعت کافی برای پر کردن خط پردازش می کنید؟ پردازش سرعت خط 10 گیگابیت بر ثانیه از کوچکترین بسته هایی که باید با آنها سروکار داشته باشیم (بسته های 64 بایتی که 84 بایت روی سیم است) معادل 14.88 میلیون بسته بر ثانیه است. چندین سیستم لینوکس که با یک Load balancer به هم متصل شده اند، هزینه، فضا، گرما و غیره زیادی را برای یک ارتباط 10 گیگابیت بر ثانیه مصرف می کنند. از طرف دیگر، میتوانید ASICهای گرانقیمت و اختصاصی تولیدکنندگان یا راهحلهای مبتنی بر FPGA را انتخاب کنید که این انتخابها نیز ارزان نخواهد بود.
پردازش برداری بستهها:
اکنون فرض کنید پردازش بستهها از قید محدودیتهای هسته سیستم عامل رها شده است و میتوان کش دادهها را به جای یک بسته در یک زمان، بر روی آرایهای از بستهها به شکل همزمان اعمال کرد. اینجاست که VPP معرفی میشود: نسخهی متن باز از تکنولوژی پردازش برداری بستههای Cisco که در محصولات ASA و CSR به کار میرود و بنابراین تکنولوژیای ثابت شده است. در اصل، VPP یک انتزاع گراف پردازش بسته ماژولار است، که در آن هر گره برداری از بستهها را پردازش میکند تا Cache thrashing را کاهش دهد، و از طریق پلاگینها قابل توسعه و تنظیم مجدد پویا میشود.
VPP حجم کاری پردازش بسته را از فضای کرنل به فضای کاربر منتقل می کند. فضای کاربر جایی است که برنامه ها و کتابخانه ها (که سیستم عامل برای تعامل با کرنل استفاده می کند، به عنوان مثال، نرم افزاری که ورودی/خروجی را انجام می دهد، آبجکتهای Filesystem را دستکاری می کند، نرم افزارهای کاربردی و غیره) در آن قرار دارند. در نتیجه، فضای کاری بسیار بیشتری برای مدیریت مجموعههای دستورالعمل مبتنی بر Cache وجود دارد.
پس از دریافت آرایهای از بستهها، VPP آن بردار را از طریق یک گراف پردازش بسته پردازش می کند:
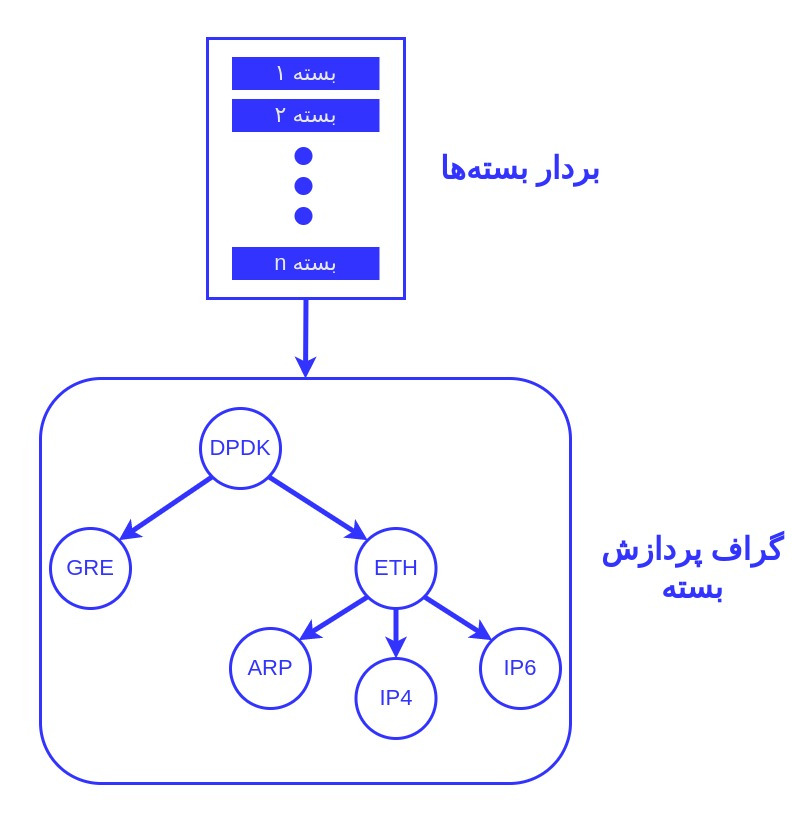
VPP به جای پردازش هر بسته از طریق کل گراف پردازش، و سپس واکشی بسته دوم و پردازش آن از طریق کل نمودار، بردار بسته ها را قبل از رفتن به گره گراف بعدی، به طور کامل از طریق گره گراف اول پردازش می کند. بسته اول در بردار instruction cache را گرم می کند، بنابراین بسته های باقی مانده را می توان بسیار سریع پردازش کرد - هزینه پردازش هر بسته بعدی در بردار را به شدت کاهش می دهد. این منجر به ۱- عملکرد بسیار بالا برای پردازش یک بسته منفرد و ۲- عملکرد قابل اعتماد آماری در پردازش تعداد زیادی بسته در طول زمان می شود. علاوه بر این، VPP اغلب آنچه را که بسته(های بعدی) می داند، از قبل واکشی می کند، و اطمینان حاصل می کند که CPU در زمانی که بسته بعدی از RAM واکشی می شود، متوقف نمی شود. در نتیجه، throughput همیشه بالا و latency به شکل پایداری پایین میباشد.
بیایید به مثال عملکرد خود در بالا برگردیم - جایی که توضیح دادیم تعدادی سیستم برای پر کردن یک لوله 10 گیگابیت در ثانیه با بسته های 64 بایتی با استفاده از پردازش هسته مورد نیاز هستند. و از آنجایی که این روزها سرعت 10 گیگابیت بر ثانیه نسبتاً رایج است، بیایید آن را کمی بالا ببریم. فرض کنید به شبکه 100 گیگابیت بر ثانیه نیاز دارید. VPP این امر را در نرم افزار قابل دستیابی می کند. 100 گیگابیت در ثانیه یک جهش 10 برابری بیش از 10 گیگابیت بر ثانیه است، بنابراین ما اکنون باید بین 8 تا 148 میلیون بسته در ثانیه پردازش کنیم - بسته به اندازه فریم بسته. اگر فریمهای بسته بزرگ باشند، میتوانیم 100 گیگابیت بر ثانیه - روی یک هسته واحد، ارسال کنیم. اگر بسته ها کوچک باشند، می توانیم 100 گیگابیت بر ثانیه را روی 10 هسته پردازش کنیم. ترافیک معمولی اینترنت ترکیبی است، بنابراین ما عملاً جایی در این بین خواهیم بود. در هر صورت، این منجر به کاهش چشمگیر هزینهها نسبت به پردازش هسته می شود.
در حالی که VPP پردازش بسته مبتنی بر نرم افزار را بسیار جذاب می کند، هنوز زمان هایی وجود دارد که شتابدهندههای سخت افزاری مناسب است. خوشبختانه، معماری گره گراف اجازه می دهد تا شتاب دهندهی سخت افزاری به راحتی اضافه شود. به عنوان مثال، برنامه های پردازش ترافیک با محاسبات سنگین مانند شتاب دهندههای رمزنگاری سخت افزاری می توانند فقط به عنوان گره گراف دیگری ظاهر شوند.